https://dx.doi.org/10.14482/inde.43.01.445.864
Transformación digital: evolución de las aplicaciones de inteligencia artificial en la industria del café
Digital transformation: evolving applications of artificial intelligence in the coffee industry
Esteban Largo Ávila*
Carlos Hernán Suárez Rodríguez**
Edwin Arango Espinal***
Correspondencia: Carlos Hernán Suárez Rodríguez. Teléfono: 2165472, Ext. 6223.
Resumen
La evolución de la Inteligencia Artificial (IA) en café es crucial para transformar esta agroindustria. Colombia produce anualmente 12.6 millones de sacos y desarrolla investigación sobre IA aplicada al sector; desde la detección de defectos en granos hasta la optimización del tueste para mejorar la calidad del café. Sin embargo, se carece de publicaciones que aborden líneas de investigación e indicadores de manera completa. En este contexto, este trabajo de investigación se fundamentó en un análisis estadístico multivariado de clúster jerárquico usado bajo la metodología de análisis bibliométrico. Este permitió inferir la tendencia actual de investigación en IA aplicada a la industria del café. Además, mediante técnicas bibliométricas de búsqueda de información se obtuvieron 208 documentos de la base de datos Scopus que fueron analizados con estadísticos descriptivos. Los resultados arrojaron que investigadores colombianos impactan significativamente la producción de conocimiento en IA aplicada al café, en comparación con Brasil, mayor productor de café. También, se identificaron líneas de investigación en análisis de mercado mediante Aprendizaje Automático (AA), tecnologías para detectar enfermedades y mejorar la productividad, métodos algorítmicos para resolver desafíos en esta agroindustria, y uso de teledetección e IA para la gestión ambiental y agrícola en la producción.
Palabras clave: café, calidad sensorial, indicadores bibliométricos, inteligencia artificial, mapeo bibliográfico.
Abstract
The evolution of Artificial Intelligence (AI) in coffee is crucial for transforming this agro-industry. Colombia annually produces 12.6 million sacks and develops research on AI applied to the sector; from the detection of defects in grains to the optimization of roasting to improve coffee quality. However, there is a lack of publications that comprehensively address research lines and indicators. In this context, this research work was based on a multivariate statistical analysis of hierarchical clustering used in the bibliometric analysis methodology. This allowed inferring the current research trend in AI applied to the coffee industry. Additionally, using bibliometric techniques for information retrieval, 208 documents from the Scopus database were refined and analyzed with descriptive statistics. The results showed that Colombian researchers significantly impact the production of knowledge in AI applied to coffee, compared to Brazil, the largest coffee producer. Furthermore, research lines in market analysis through Machine Learning (ML), technologies to detect diseases and improve productivity, algorithmic methods to solve challenges in this agro-industry, and the use of remote sensing and AI for environmental and agricultural management in production were identified.
Keywords: artificial intelligence, bibliometric indicators, bibliographic mapping, coffee, sensory quality.
Fecha de recepción: 26 de febrero de 2024
Fecha de aceptación: 25 de julio de 2024
INTRODUCCIÓN
El café representa un sustento vital para pequeños productores, quienes enfrentan desafíos económicos y ambientales, como la crisis climática y los bajos ingresos. En medio de la adversidad, el café se valora en los mercados por su calidad. Esto puede conllevar un aumento en los precios de origen y a implementar mejoras en los sistemas de cultivo, promoviendo así prácticas sostenibles y diversificadas [1]. Latinoamérica lidera la producción y exportación mundial de café, con Brasil contribuyendo aproximadamente al 25 % de las exportaciones globales y Colombia ocupando el segundo lugar con una producción anual de aproximadamente 12.6 millones de sacos [2]. Estos países han explorado tecnologías emergentes como la IA para analizar y optimizar su producción y el mercado del café, con algoritmos de AA, análisis predictivo y aprendizaje profundo (AP) para mejorar los procesos en el cultivo, cosecha y postcosecha.
Se han incorporado tecnologías de Machine Learning (ML) y visión multiespectral para automatizar la evaluación de la calidad de los granos, detectando eficientemente anomalías. Además, se utiliza la detección automática de frutos mediante visión por computadora (VC) para estimar el rendimiento durante la cosecha y anticipar tendencias y fluctuaciones en la demanda durante la comercialización [3], [4]. Esto evidencia un significativo interés en la investigación sobre la aplicación de IA en la agroindustria del café.
Este documento se centra en el uso de análisis multivariado de clúster jerárquico para realizar un acoplamiento bibliográfico y agrupar términos relevantes [5]. Para ello, se utilizó el software VOSviewer, que combina algoritmos de extracción y filtrado de términos y reduce la dimensionalidad mediante el algoritmo VOS. Este proceso permitió analizar la evolución del conocimiento respecto a las aplicaciones de inteligencia artificial en la industria del café, para proponer las futuras líneas de investigación articuladas a la revisión de publicaciones recientes. En la sección de metodología se detalla el procedimiento de análisis multivariado de clúster jerárquico realizado, proporcionando así una base sólida para las conclusiones obtenidas. La estructura del documento comprende cinco secciones, así: introducción, marco teórico, metodología, resultados y conclusiones; en esta última se presentan las limitaciones, líneas y proyectos de investigación para trabajos futuros.
MARCO TEÓRICO
El análisis bibliométrico es una técnica rigurosa, ampliamente utilizada para examinar vastos volúmenes de datos científicos a través de la estadística, facilitando la comprensión de la evolución de un campo del saber [6]. Esta herramienta permite realizar análisis de redes de visualización, identificar autores y artículos influyentes, así como clústeres de investigación [7], y es fundamental para representar los avances académicos y científicos en diversas estructuras conceptuales [8].
La cocitación tiene lugar cuando una tercera publicación cita dos documentos al mismo tiempo, indicando similitud temática desde la perspectiva del citante [9], [10]. El análisis de cocitación de autores, introducido por [11], se da cuando un autor cita tanto su propio trabajo como el de otros autores [12]. El acoplamiento bibliográfico se produce cuando dos publicaciones comparten citas hacia una tercera publicación [13], y su análisis se usa para mapear autores activos y entender sus actividades de investigación de manera objetiva y actualizada [14].
Los indicadores bibliométricos proporcionan una visión actualizada del estado de la IA en la agroindustria del café, ofreciendo un marco de referencia para investigadores y futuros estudios. Aunque su uso en este contexto está poco desarrollado, algunas investigaciones exploran técnicas de precisión y agricultura 4.0 para fomentar la sostenibilidad, la certificación internacional y la investigación agronómica [15], [16], [17]. Sin embargo, se carece de literatura actual que aborde la IA en la agroindustria del café bajo esta metodología.
METODOLOGÍA
Este estudio sigue el proceso metodológico propuesto por [18], que considera las siguientes etapas:
Selección de fuentes de datos
Se eligió la base de datos Scopus debido a su amplia influencia y cobertura multidisciplinaria en la literatura científica. Destacada por su riguroso proceso de indexación, asegura la inclusión de publicaciones relevantes y proporciona información detallada sobre las publicaciones [19].
Definición de tesauros de búsqueda
Posterior al proceso de filtrado de la información y optimización de búsqueda se obtuvieron 208 documentos hasta enero de 2024 que estudian el café e IA; esto se logró mediante la ecuación de búsqueda (TITLE-ABS-KEY (coffee) AND TITLE-ABS-KEY ("artificial intelligence")), siguiendo el proceso de elegibilidad de registros descrito en la figura 1.
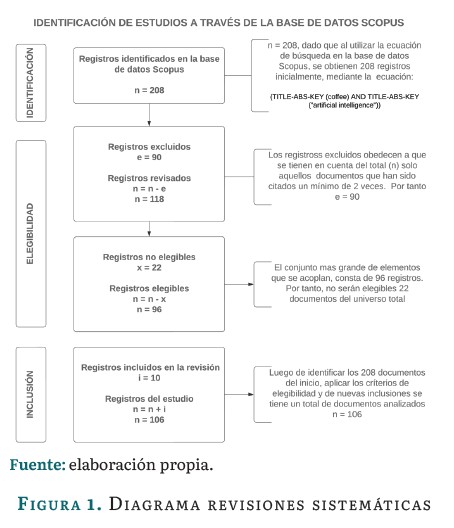
Análisis de la Información, construcción de indicadores y futuras líneas de investigación
Se descargó información relevante de la base de datos Scopus en un archivo con formato CSV. Una vez obtenidos los artículos, se clasificaron y organizaron según criterios como año de publicación, autor, fuentes y país. Se usaron herramientas descriptivas de la base de datos Scopus para calcular indicadores bibliométricos, se crearon tablas y gráficos que permitieron analizar aspectos como la producción en el tiempo, revistas destacadas, países con mayor producción, autores con más publicaciones y artículos más citados.
Posteriormente, con el software especializado VOSviewer [20] se crearon las redes de acoplamiento bibliográfico y coocurrencia de términos, para visualizar la información agrupada en clústeres; estos se describieron y mediante un análisis de inferencia de la información se definieron tendencias actuales y futuras líneas de investigación.
RESULTADOS Y DISCUSIÓN
Evolución de la producción científica en el tiempo
La figura 2 muestra la tendencia de publicaciones en el tiempo.
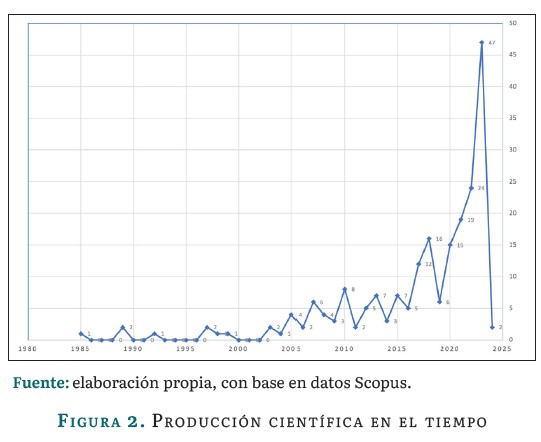
Se nota un incremento en la producción científica durante el periodo comprendido entre 2005 y 2010, seguido de un declive. Desde 2011 hasta 2016, la producción se mantuvo estable. Sin embargo, desde 2017 hasta enero de 2024 se registra un crecimiento exponencial con 141 documentos, representando el 68 % de las publicaciones en IA aplicada a la agroindustria del café.
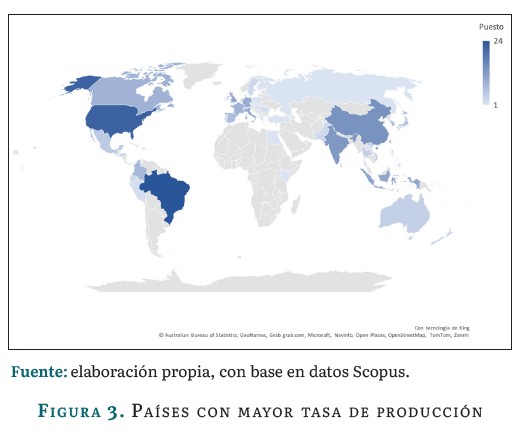
Países con mayor tasa de producción
La figura 3 muestra la producción científica sobre IA en la agroindustria del café. Brasil lidera con 24 documentos, constituyendo el 12 % de la producción. Sigue Estados Unidos con 22 artículos (11 %), luego China, con 14 documentos (7 %), en tercer lugar. Indonesia y el Reino Unido ocupan el cuarto y quinto lugar, con 11 documentos cada uno, representando el 5 % de la producción, respectivamente.
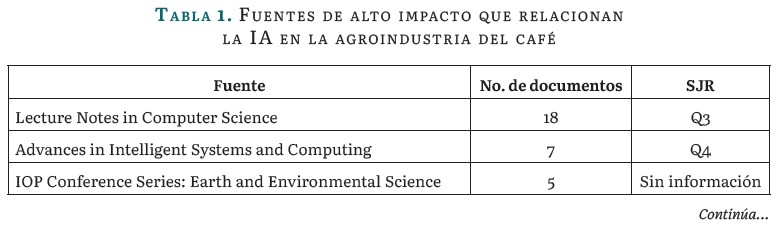
Fuentes de considerable impacto
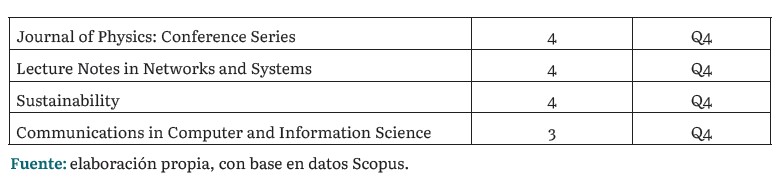
La tabla 1 presenta las principales revistas y series de libros que incluyen actas de conferencias, donde se abordan el campo de estudio. Encabezando la lista se encuentra la serie de libros Lecture Notes in Computer Science de Alemania, clasificada en el SJR-Q3, con 18 documentos. Le sigue Advances in Intelligent Systems and Computing de Alemania, clasificada en el SJR-Q4 hasta 2021, con 7 documentos. La IOP Conference Series: Earth and Environmental Science del Reino Unido ocupa el tercer lugar con 5 documentos. Otras publicaciones destacadas incluyen Journal of Physics: Conference Series del Reino Unido, Lecture Notes in Networks and Systems de Suiza, y Sustainability de Suiza, cada una con 4 publicaciones y clasificadas en SJR-Q4, SJR-Q4 y SJR-Q3, respectivamente. En quinto lugar se encuentra la revista Communications in Computer and Information Science, también clasificada en SJR-Q4, con 3 publicaciones. Esto refleja el interés y la relevancia de este campo en revistas de alto impacto.
Escritores más prolíficos
La tabla 2 presenta un resumen de los autores con mayor cantidad de publicaciones en el área.
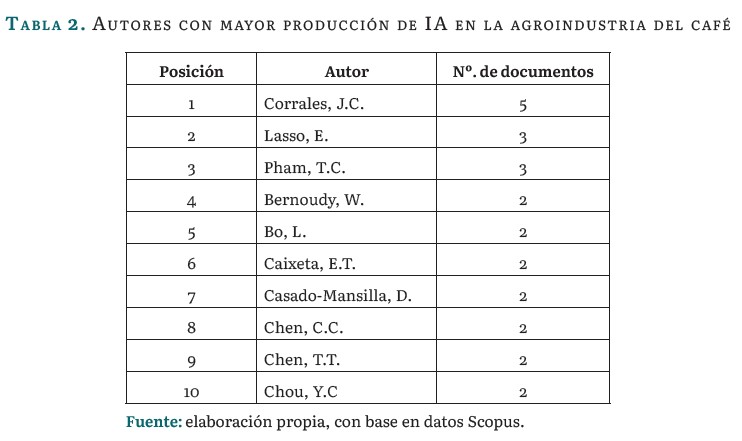
Juan Carlos Corrales y Emmanuel Gerardo Lasso, de la Universidad del Cauca, en Colombia, lideran la investigación en técnicas de IA para detectar la roya del café. Su modelo basado en grafos mejora la interpretación de las reglas de detección [22]. Adicionalmente, proponen un sistema de alerta para enfermedades y plagas en cultivos de café, mediante tecnologías Big Data y AA [23]. En el estudio [24] se usan algoritmos de aprendizaje supervisado para detectar la roya en cultivos de café, aprovechando datos sobre propiedades del suelo, clima y manejo del cultivo. También, se proponen métodos de AA para ampliar las muestras de roya y se desarrolla un sistema de apoyo basado en conocimiento de expertos. Este sistema sugiere la aplicación de fungicidas y servicios adicionales integrados con un Sistema de Alerta Temprana (SAT) para la roya del café, ofreciendo una solución flexible y escalable [25].
En tercer lugar, en [26] se promueven prácticas agrícolas sostenibles y tecnológicamente avanzadas en la agroindustria del café, se presenta la plataforma INNSA para una cadena de valor sostenible del café en Vietnam y proponen métodos de AP para mejorar la clasificación de enfermedades del café, se busca elevar la calidad y valor añadido de la cadena de suministro con tecnologías como dispositivos inteligentes, IoT, big data, IA, blockchain y trazabilidad, mediante una base de datos inteligente con actualizaciones en tiempo real [27].
Otros autores contribuyen al campo de estudio cada uno con dos publicaciones; [28] presenta el marco Object-Pose Tree para el reconocimiento eficiente de miles de poses de objetos en tiempo real. Optimiza las tareas de reconocimiento de categorías, instancias y poses, superando las clasificaciones estándar y mostrando un reconocimiento robusto en objetos cotidianos complejos. De otra parte, en [29] estudian la selección genómica para predecir la resistencia a la roya naranja en el café Arábica. Comparan métodos estadísticos y de AA como redes neuronales y regresión lineal bayesiana; las redes neuronales identificaron más marcadores y tuvieron una tasa de error de predicción más baja [30].
En el estudio de [31] se desarrolló una infraestructura RESTful para reducir el consumo energético de máquinas de café conectadas a internet en espacios de trabajo; se logró la estimación de la predicción del consumo energético de la semana de trabajo siguiente usando modelos ARIMA, fundamentándose en datos empíricos obtenidos de cuatro máquinas de café. El sistema HCADIS, propuesto por [32], usa la Transformada de Hough para detectar defectos en granos de café densos como parte de un proceso de eliminación de defectos basado en cámaras. Esta combina datos de una red profunda con la Transformada de Hough para inspeccionar con precisión los granos defectuosos, ofreciendo valiosas soluciones para la industria del café. Por último, [33] presenta un sistema de inspección de granos de café defectuosos basado en AP, denominado DL-DBIS y un método automático de aumento de datos denominado GALDAM. El sistema DL-DBIS identifica defectos entre granos densos, mientras que GALDAM reduce costos al automatizar el etiquetado de datos.
En síntesis, los científicos aportan soluciones innovadoras para la industria cafetera, utilizando IA para detectar plagas y desarrollar sistemas de alerta. Se proponen tecnologías optimizar el consumo de energía y esquemas de control para detectar defectos en granos de café. Estas soluciones buscan mejorar la eficiencia y sostenibilidad en la producción y procesamiento del café, impulsando avances en el sector mediante la combinación de tecnología y análisis de datos.
Publicaciones más citadas
En bioinformática, se destaca un trabajo citado más de 3000 veces, enfocándose en la evolución de métodos de alineamiento de secuencias de ADN y proteínas, subrayando la necesidad de métodos más avanzados debido al crecimiento de datos y descubrimientos recientes [34]. Por otro lado, con 227 citaciones, se exploran avances en lenguas electrónicas y sensores del gusto, utilizados para distinguir líquidos similares mediante respuestas eléctricas diferenciales en aplicaciones como el análisis de vinos y la detección de impurezas en aguas [35].
Con 167 y 137 citaciones, respectivamente, el estudio [36] presenta el modelo Secuencia de Actomas para localizar acciones en datos de video, utilizando unidades de acción llamadas actoms, mientras que [37] emplea IA en la comparación semántica de entidades como té y café, evaluando similitudes mediante modelos de procesamiento de lenguaje natural.
Otro estudio, con 135 citaciones, propone mejoras al método DIALIGN para el alineamiento múltiple de proteínas, superando limitaciones previas con un algoritmo de encadenamiento de fragmentos mejorado [38]. Además, destaca el uso de modelos de aprendizaje extremo en un estudio con 103 citaciones, para predecir el rendimiento del café robusta basándose en datos de propiedades del suelo [39].
En términos de VC, se presenta un modelo avanzado para modelar interacciones persona-objeto en vídeos realistas, artículo que alcanza 84 citaciones [40]. Otro estudio, con 83 citaciones, desarrolla un sistema basado en redes neuronales para evaluar y clasificar el color de granos de café verde según estándares específicos [41]. Finalmente, con 70 citaciones, se mencionan desarrollos como MediaCup, una taza de café inteligente que recopila y transmite información contextual, y la impresión de transistores de óxidos metálicos mediante tecnología de impresión de inyección de tinta [42], [43].
Estos avances reflejan la aplicación diversa y multidisciplinaria de técnicas avanzadas como IA y aprendizaje extremo en campos como la bioinformática y la producción de café, promoviendo resultados precisos y aplicaciones prácticas en la agroindustria.
Acoplamiento bibliográfico
El acoplamiento bibliográfico evalúa la similitud entre documentos mediante elementos compartidos en las referencias, destacando la relevancia de las publicaciones dentro de la red [44], [45]. Utilizando VOSviewer [20], se identificaron cuatro enfoques distintos de investigación en esta red. El análisis emplea estadísticas multivariadas para mejorar las redes de acoplamiento, considerando métricas como el número total de nodos, el grado medio y la densidad del grafo [46]. VOSviewer [20] aplica algoritmos de estimación y técnicas de normalización de la fuerza de asociación, como se muestra en la figura 4.

Exploración de las corrientes científicas actuales sobre el café, incorporando (IA)
Clúster 1 (rojo) - Análisis y clasificación de noticias sobre el mercado del café
En esta área de investigación se utilizan técnicas de análisis de datos y la clasificación de textos para apoyar la toma de decisiones en el desarrollo de productos y el monitoreo del mercado del café. Por ejemplo, el análisis de opiniones en línea impulsa el desarrollo de productos a través del marco inteligente I-Kano [47]. Además, el clasificador Naïve-Bayes se utiliza con éxito para categorizar noticias web sobre el mercado del café, identificando factores relevantes [48]. Se propone también un sistema de toma de decisiones centrado en cultivos como el arroz, el café y el cacao para mejorar la eficiencia y reducir costos [49]. Finalmente, se exploran técnicas de análisis avanzado para clasificar noticias del mercado del café según categorías de la cadena de suministro, destacando el rendimiento de los algoritmos basados en Naïve-Bayes [50].
Clúster 2 (verde) - SmartCafé: Tecnología e IA para la agricultura
Esta corriente de investigación se centra en tecnologías avanzadas como la IA y el análisis de datos para prevenir enfermedades en cultivos de café. Se destaca el uso de IA para la detección y control de enfermedades agrícolas como la roya del café [22]. Además, la agricultura inteligente, apoyada en tecnologías como big data, busca mejorar la gestión de datos agrícolas y prevenir enfermedades y plagas de manera anticipada [25]. También se explora el uso de cámaras digitales para mediciones no destructivas como herramienta prometedora para el monitoreo agrícola en cultivos como el café y el cacao, proponiendo protocolos para su implementación efectiva [51].
Clúster 3 (azul) -Algoritmos y AA para la innovación en café
En este campo de investigación se desarrollan métodos algorítmicos para predecir respuestas sensoriales y detectar tempranamente la roya del café. La investigación en olfacción mecánica, que se centra en anticipar la respuesta de sensores a mezclas de olores, propone una solución algorítmica combinando técnicas de señales y máquinas de vectores de soporte (SVM). Esta solución ha mostrado ser efectiva al correlacionarse con las respuestas reales del sensor [52]. Sin embargo, los algoritmos de aprendizaje supervisado enfrentan desafíos debido a la escasez de datos en la detección de la roya del café, por lo que se recomienda aumentar las muestras utilizando métodos de inteligencia artificial. Se sugiere llevar a cabo una revisión sistemática para mejorar la representación de la enfermedad en los conjuntos de datos [53], [54].
Clúster 4 (amarillo) - Teledetección en la agricultura, ambiente y cultivos de café
La investigación se enfoca en la aplicación de la teledetección y la (IA) para la cartografía de ecosistemas forestales y la optimización de la producción agrícola. En los estudios [55], [56] se subraya el potencial de estas tecnologías en la gestión ambiental y agrícola. La clasificación de máxima verosimilitud ha demostrado ser efectiva en la cartografía del bosque atlántico semicaducifolio, mientras que el Perceptrón Multicapa ha sido exitoso en la estimación del volumen de los cafetales, facilitando la aplicación precisa de productos fitosanitarios. Además, la clasificación con descriptores temporales de textura mejora la precisión en la cartografía, especialmente en cultivos como el café, donde el Perceptrón Multicapa permite una agricultura más eficiente y sostenible al estimar el volumen de los cafetos.
Red de coocurrencia de términos
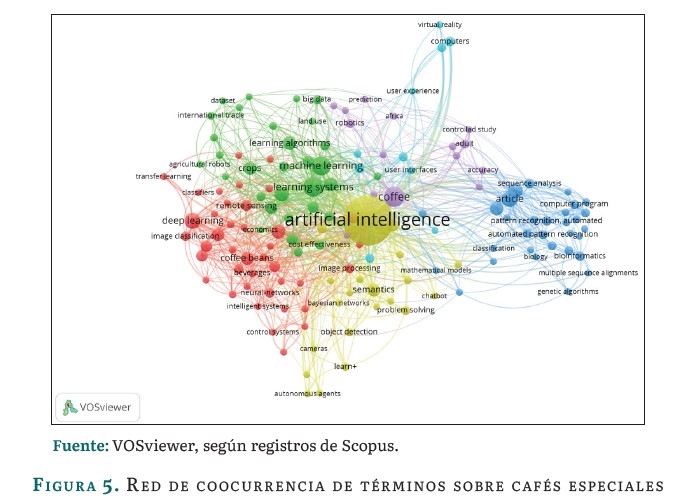
La figura 5 ilustra la red de coocurrencia de términos generada con el software VOSviewer [20], se identifican 11 clústeres de palabras basados en la frecuencia de aparición de los términos, y se describen las cinco principales agrupaciones mediante un conteo fraccionado.
Análisis de clúster
El clúster 1, en rojo, se enfoca en la tecnología, la IA y el procesamiento de imágenes en la industria alimentaria, especialmente en la producción y control de calidad del café, resaltando la seguridad alimentaria y la calidad de los productos agrícolas, enfocándose principalmente en el café. El clúster 2, en verde, destaca la interdisciplinariedad entre la informática y la biología, impulsando el desarrollo de algoritmos y software especializados para analizar secuencias genéticas y estudiar la biología molecular. El clúster 3, en azul, aborda temas agrícolas, análisis de datos y tecnología aplicada al sector agrícola. El clúster 4, en amarillo, incluye conceptos de tecnología e informática, como IA, automatización, chatbots y procesamiento del lenguaje natural. Finalmente, el clúster 5, en morado, se centra en la IA y la ciencia de la computación, destacando su impacto en la vida cotidiana, desde algoritmos avanzados hasta IoT y sostenibilidad, incluyendo realidad virtual e interfaces fáciles de usar.
CONCLUSIONES
Se obtuvieron cuatro clústeres al realizar el acoplamiento bibliográfico y la coocurrencia de términos. Esto evidencia un campo del conocimiento novedoso, que se ha consolidado en los últimos cinco años. El análisis bibliométrico destaca el significativo impacto de la IA en la agroindustria cafetera, siendo 2023 el año el más productivo, con un total de 47 publicaciones en revistas de alto impacto, varias clasificadas como SJR-Q3.
Brasil, como el principal productor mundial de café, es el país más activo en investigación que vincula la IA con la agroindustria del café. Sin embargo, Colombia se reconoce por tener los autores más prolíficos, ocupando los primeros lugares en este campo de investigación. Las contribuciones se enfocan en las técnicas de IA, específicamente la inducción de árboles de decisión y el conocimiento experto para detectar la roya en café.
El análisis de clúster permitió inferir que el uso de AA en la agroindustria del café es innovador y prometedor, con investigaciones que abordan desde el mercado del café hasta sistemas como Smart Café para mejorar la toma de decisiones y obtener nuevas perspectivas de innovación en el sector del café.
Limitaciones y futuras líneas de investigación
Este estudio se basó en una muestra de la base de datos Scopus, lo que implica ciertas limitaciones en el alcance. Se sugiere considerar otras bases de datos como Web of Science para futuras investigaciones, con el fin de obtener una caracterización más completa y comparativa.
Se propone desarrollar un sistema integrado de monitoreo y predicción para la gestión de fincas cafeteras, empleando tecnologías de VC y análisis avanzado. Este sistema podría explorar la integración de sistemas de visión multiespectral con algoritmos de AA, como YOLOv7, para monitorear y predecir la maduración del café en tiempo real.
También, se propone el desarrollo de prototipos de monitoreo, mediante la implementación de sistemas de monitoreo basados en cámaras digitales y sensores de bajo costo, diseñados para realizar mediciones no destructivas en cultivos de café, con un enfoque diferenciado para pequeños productores.
Además, se recomienda utilizar métodos semisupervisados de anotación de imágenes para mejorar la precisión y eficacia del seguimiento de la maduración del café en el campo, durante la cosecha y postcosecha.
Por último, se sugiere desarrollar sistemas de evaluación sensorial de la calidad del café que integren tecnologías de nariz electrónica (E-nose) y AA. Estos sistemas podrían explorar diversas combinaciones de sensores de gas y algoritmos de AA para mejorar la precisión, eliminar la subjetividad y permitir la reproducibilidad en procesos de catación.
AGRADECIMIENTOS
Se agradece a la Universidad del Valle, sede regional Caicedonia por su apoyo en el desarrollo de la investigación. Asimismo, se reconoce al laboratorio de cafés especiales Roast Lab Univalle por su papel como escenario de investigación aplicada que impacta a los diversos actores del Paisaje Cultural Cafetero Colombiano (PCCC). Finalmente, Al Grupo de Investigación, Innovación y Desarrollo en Café especiales (GIIDCE).
* Profesor asociado, Universidad del Valle, Vicerrectoría de Regionalización, sede regional Caicedonia, Valle del Cauca (Colombia). Ph.D. Ingeniería - Sistemas Energéticos. Orcid-ID: https://orcid.org/0000-0001-6047-1523. esteban.largo@correounivalle.edu.co
** Profesor asociado, Universidad del Valle, Vicerrectoría de Regionalización, sede regional Caicedonia, Valle del Cauca (Colombia). M.Sc. Sistemas Integrados de Gestión de la Calidad. Orcid-ID: https://orcid.org/0000-0002-1304-3646. carlos.hernan.suarez@correounivalle.edu.co
*** Profesor asociado, Universidad del Valle, Vicerrectoría de Regionalización, sede regional Caicedonia, Valle del Cauca (Colombia). Ph.D. Administración. Orcid-ID: https://orcid.org/0000-0002-2231-3513. edwin.arango@correounivalle.edu.co
REFERENCIAS
[1] J. Jacobi et al., "Making specialty coffee and coffee-cherry value chains work for family farmers' livelihoods: A participatory action research approach", World Dev Perspect, vol. 33, p. 100551, marzo 2024. doi: 10.1016/j.wdp.2023.100551.
[2] International Coffee Organization, "Statistical Database. International Coffee Organization". https://www.ico.org/pt/Market-Report-22-23-p.aspx.
[3] Y. Liu et al., "Evaporative self-assembling bioconcentrators onto superhydrophobic micropyramidal arrays as rapid and intelligent blood cancer filtering platforms", Sens ActuatorsBChem, vol. 393, p. 134330, oct. 2023. doi: 10.1016/j.snb.2023.134330.
[4] F. Eron, M. Noman, R. R. de Oliveira y A. Chalfun-Junior, "Computer Vision-Aided Intelligent Monitoring of Coffee: Towards Sustainable Coffee Production", Sci Hortic, vol. 327, p. 112847, marzo 2024. doi: 10.1016/j.scienta.2024.112847.
[5] G. González-Alcaide, A. Calafat, y E. Becoña, "Núcleos y ámbitos de investigación sobre adicciones en España a través del análisis de los enlaces bibliográficos en la Web of Science (2000-2013)", Adicciones, vol. 26, n°. 2, p. 168, juni 2014. doi: 10.20882/adicciones.20.
[6] N. Donthu, S. Kumar, D. Mukherjee, N. Pandey y W. M. Lim, "How to conduct a bibliometric analysis: An overview and guidelines", J Bus Res, vol. 133, pp. 285-296, sep. 2021. doi: 10.1016/j.jbusres.2021.04.070.
[7] N. Ye, T.-B. Kueh, L. Hou, Y. Liu y H. Yu, "A bibliometric analysis of corporate social responsibility in sustainable development", J Clean Prod, vol. 272, p. 122679, nov. 2020. doi: 10.1016/j.jclepro.2020.122679.
[8] S. Kaffash, A. T. Nguyen y J. Zhu, "Big data algorithms and applications in intelligent transportation system: A review and bibliometric analysis", Int J Prod Econ, vol. 231, p. 107868, enero 2021. doi: 10.1016/j.ijpe.2020.107868.
[9] H. Small, "Co-citation in the scientific literature: A new measure of the relationship between two documents", Journal of the American Society for Information Science, vol. 24, n°. 4, pp. 265-269, julio 1973. doi: 10.1002/asi.4630240406.
[10] S. Miguel, F. Moya-Anegón y V. Herrero-Solana, "El análisis de co-citas como método de investigación en Bibliotecología y Ciencia de la Información", Investigación Bibliotecológica: archivonomía, bibliotecología e información, vol. 21, n°. 43, julio 2007. doi: 10.22201/iibi.0187358xp.2007.43.4129.
[11] H. D. White y B. C. Griffith, "Author cocitation: A literature measure of intellectual structure", Journal of the American Society for Information Science, vol. 32, n°. 3, pp. 163171, mayo 1981. doi: 10.1002/asi.4630320302.
[12] H. D. White y K. W. McCain, "Visualizing a discipline: An author co-citation analysis of information science, 1972-1995", Journal of the American Society for Information Science, vol. 49, no. 4, pp. 327-355, 1998. doi: 10.1002/(SICI)1097-4571(19980401)49:4<327: AID-ASI4>3.0.CO;2-4.
[13] M. M. Kessler, "Bibliographic coupling between scientific papers", American Documentation, vol. 14, n°. 1, pp. 10-25, enero 1963. doi: 10.1002/asi.5090140103.
[14] D. Zhao y A. Strotmann, "Evolution of research activities and intellectual influences in information science 1996-2005: Introducing author bibliographic-coupling analysis", Journal of the American Society for Information Science and Technology, vol. 59, n°. 13, pp. 2070-2086, nov. 2008. doi: 10.1002/asi.20910.
[15] L. C. Cabrera, C. E. Caldarelli y M. R. G. da Camara, "Mapping collaboration in international coffee certification research", Scientometrics, vol. 124, n°. 3, pp. 2597-2618, sep. 2020. doi: 10.1007/s11192-020-03549-8.
[16] Y. M. Guimarães, J. H. P. P. Eustachio, W. Leal Filho, L. F. Martinez, M. R. do Valle y A. C. F. Caldana, "Drivers and barriers in sustainable supply chains: The case of the Brazilian coffee industry", Sustain Prod Consum, vol. 34, pp. 42-54, nov. 2022. doi: 10.1016/j.spc.2022.08.031.
[17] H. Madrid-Casaca, G. Salazar-Sepúlveda, N. Contreras-Barraza, M. Gil-Marín y A. Vega-Muñoz, "Global Trends in Coffee Agronomy Research", Agronomy, vol. 11, n°. 8, p. 1471, julio 2021. doi: 10.3390/agronomy11081471.
[18] A. R. Orejuela, C. Fernando, O. Andrade y J. Peláez Muñoz, "Two decades of research in Electronic Word of Mouth: a bibliometric analysis", Pensamiento & gestión, vol. 48, pp. 265-282, 2020.
[19] S. Kumar, N. Pandey, W. M. Lim, A. N. Chatterjee y N. Pandey, "What do we know about transfer pricing? Insights from bibliometric analysis", J Bus Res, vol. 134, pp. 275287, sep. 2021. doi: 10.1016/j.jbusres.2021.05.041.
[20] N. J. Van Eck y L. Waltman, "VOSviewer Manual", https://www.vosviewer.com/documentation/Manual_VOSviewer_1.6.18.pdf .
[21] P. P. Bonissone y K. P. Valavanis, "COMPARATIVE STUDY OF DIFFERENT APPROACHES TO QUALITATIVE PHYSICS THEORIES", 1985.
[22] E. Lasso, T. T. Thamada, C. A. A. Meira y J. C. Corrales, "Communications in Computer and Information Science 544 Editorial Board", Manchester, 2015 [En línea]. Disponible en: http://www.springer.com/series/7899
[23] P. Angelov, J. Antonio, I. Juan y C. Corrales, "Advances in Intelligent Systems and Computing 687 Advances in Information and Communication Technologies for Adapting Agriculture to Climate Change", 2017 [En línea]. Disponible en: http://www.springer.com/series/11156
[24] J. P. Rodríguez, D. C. Corrales y J. C. Corrales, "A Process for Increasing the Samples of Coffee Rust Through Machine Learning Methods", International Journal of Agricultural and Environmental Information Systems, vol. 9, n°. 2, pp. 32-52, abril 2018. doi: 10.4018/ IJAEIS.2018040103.
[25] E. Lasso, S. Valencia y J. C. Corrales, "Computational Science and Its Applications -ICCSA 2017", vol. 10405, en Lecture Notes in Computer Science, vol. 10405. Cham: Springer International Publishing, 2017. doi: 10.1007/978-3-319-62395-5.
[26] T. C. Pham, V. D. Nguyen, C. H. Le, M. Packianather y V.-D. Hoang, "Artificial intelligence-based solutions for coffee leaf disease classification", IOP Conf Ser Earth Environ Sci, vol. 1278, n°. 1, p. 012004, dic. 2023. doi: 10.1088/1755-1315/1278/1/012004.
[27] V. D. Nguyen, T. C. Pham, C. H. Le, T. T. Huynh, T. H. Le y M. Packianather, "An Innovative and Smart Agriculture Platform for Improving the Coffee Value Chain and Supply Chain", 2023, pp. 185-197. doi: 10.1007/978-981-19-6450-3.19.
[28] L. Bo, K. Lai, X. Ren y D. Fox, "A Scalable Tree-Based Approach for Joint Object and Pose Recognition", Proceedings of the AAAI Conference on Artificial Intelligence, vol. 25, n°. 1, pp. 1474-1480, Aug. 2011. doi: 10.1609/aaai.v25i1.7986.
[29] E. T. Caixeta et al., "Genomic prediction of leaf rust resistance to Arabica coffee using machine learning algorithms", Sci Agric, vol. 78, n°. 4, 2021. doi: 10.1590/1678-992x-2020-0021.
[30] E. T. Caixeta et al., "Artificial neural networks compared with Bayesian generalized linear regression for leaf rust resistance prediction in Arabica coffee", Pesqui Agropecu Bras, vol. 52, n°. 3, pp. 186-193, marzo 2017. doi: 10.1590/s0100-204x2017000300009.
[31] D. Casado-Mansilla, J. López-de-Armentia, P. Garaizar, D. López-de-Ipiña, V. Catania y D. Ventura, "ARIIMA: A Real IoT Implementation of a Machine-Learning Architecture for Reducing Energy Consumption", 2014, pp. 444-451. doi: 10.1007/978-3-319-13102-3_72.
[32] C.-C. Chen et al., "Improving Defect Inspection Quality of Deep-Learning Network in Dense Beans by Using Hough Circle Transform for Coffee Industry", in 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), IEEE, oct. 2019, pp. 798805. doi: 10.1109/SMC.2019.8914175.
[33] T.-T. Chen et al., "Deep-Learning-Based Defective Bean Inspection with GAN-Structured Automated Labeled Data Augmentation in Coffee Industry", Applied Sciences, vol. 9, n°. 19, p. 4166, oct. 2019. doi: 10.3390/app9194166.
[34] K. Katoh and H. Toh, "Recent developments in the MAFFT multiple sequence alignment program", Brief Bioinform, vol. 9, n°. 4, pp. 286-298, marzo 2008. doi: 10.1093/bib/ bbn013.
[35] A. Riul Jr., C. A. R. Dantas, C. M. Miyazaki y O. N. Oliveira Jr., "Recent advances in electronic tongues", Analyst, vol. 135, n°. 10, p. 2481, 2010. doi: 10.1039/c0an00292e.
[36] A. Gaidon, Z. Harchaoui y C. Schmid, "Temporal Localization of Actions with Actoms", IEEE Trans Pattern Anal Mach Intell, vol. 35, n°. 11, pp. 2782-2795, nov. 2013. doi: 10.1109/ TPAMI.2013.65.
[37] S. Harispe, S. Ranwez, S. Janaqi y J. Montmain, Semantic Similarity from Natural Language and Ontology Analysis. Cham: Springer International Publishing, 2015. doi: 10.1007/9783-031-02156-5.
[38] A. R. Subramanian, J. Weyer-Menkhoff, M. Kaufmann y B. Morgenstern, "DIALIGN-T: An improved algorithm for segment-based multiple sequence alignment", BMC Bioinformatics, vol. 6, n°. 1, p. 66, 2005. doi: 10.1186/1471-2105-6-66.
[39] L. Kouadio, R. C. Deo, V. Byrareddy, J. F. Adamowski, S. Mushtaq y V. Phuong Nguyen, "Artificial intelligence approach for the prediction of Robusta coffee yield using soil fertility properties", Comput Electron Agric, vol. 155, pp. 324-338, dic. 2018. doi: 10.1016/j. compag.2018.10.014.
[40] A. Prest, V. Ferrari y C. Schmid, "Explicit Modeling of Human-Object Interactions in Realistic Videos", IEEE Trans Pattern Anal Mach Intell, vol. 35, n°. 4, pp. 835-848, abril 2013. doi: 10.1109/TPAMI.2012.175.
[41] E. M. de Oliveira, D. S. Leme, B. H. G. Barbosa, M. P. Rodarte y R. G. F. A. Pereira, "A computer vision system for coffee beans classification based on computational intelligence techniques", J Food Eng, vol. 171, pp. 22-27, feb. 2016. doi: 10.1016/j. jfoodeng.2015.10.009.
[42] H.-W. Gellersen, M. Beigl y H. Krull, "The MediaCup: Awareness Technology Embedded in an Everyday Object", 1999, pp. 308-310. doi: 10.1007/3-540-48157-5.30.
[43] W. J. Scheideler, R. Kumar, A. R. Zeumault y V. Subramanian, "Low-Temperature-Processed Printed Metal Oxide Transistors Based on Pure Aqueous Inks", Adv Funct Mater, vol. 27, n°. 14, abril 2017. doi: 10.1002/adfm.201606062.
[44] C. Veloutsou y C. Ruiz Mafe, "Brands as relationship builders in the virtual world: A bibliometric analysis", Electron Commer Res Appl, vol. 39, p. 100901, enero 2020. doi: 10.1016/j.elerap.2019.100901.
[45] A. Caputo, S. Pizzi, M. M. Pellegrini y M. Dabic, "Digitalization and business models: Where are we going? A science map of the field", J Bus Res, vol. 123, pp. 489-501, feb. 2021. doi: 10.1016/j.jbusres.2020.09.053.
[46] M. J. Cobo, A. G. López-Herrera, E. Herrera-Viedma y F. Herrera, "Science mapping software tools: Review, analysis, and cooperative study among tools", Journal of the American Society for Information Science and Technology, vol. 62, n°. 7, pp. 1382-1402, julio 2011. doi: 10.1002/asi.21525.
[47] D. Chen, D. Zhang y A. Liu, "Intelligent Kano classification of product features based on customer reviews", CIRP Annals, vol. 68, n°. 1, pp. 149-152, 2019. doi: 10.1016/j. cirp.2019.04.046.
[48] P. Oliveira Lima Junior, L. Gonzaga de Castro Junior y A. Luiz Zambalde, "Applying Textmining to Classify News About Supply and Demand in the Coffee Market", IEEE Latin America Transactions, vol. 14, n°. 12, pp. 4768-4774, dic. 2016. doi: 10.1109/ TLA.2016.7817009.
[49] K. Lagos-Ortiz, J. Medina-Moreira, A. Alarcón-Salvatierra, M. F. Morán, J. del Cioppo-Morstadt y R. Valencia-García, "Decision Support System for the Control and Monitoring of Crops", 2019, pp. 20-28. doi: 10.1007/978-3-030-10728-4.3.
[50] P. Oliveira Lima Junior, L. Gonzada de Castro Junior y A. Luiz Zambalde, "Analysis of Machine Learning Techniques to Classify News for Information Management in Coffee Market", IEEE Latin America Transactions, vol. 13, n°. 7, pp. 2285-2291, julio 2015. doi: 10.1109/TLA.2015.7273789.
[51] B. T. W. Putra, P. Soni, B. Marhaenanto, Pujiyanto, S. Sisbudi Harsono y S. Fountas, "Using information from images for plantation monitoring: A review of solutions for smallholders," Information Processing in Agriculture, vol. 7, n°. 1, pp. 109-119, marzo 2020. doi: 10.1016/j.inpa.2019.04.005.
[52] E. Phaisangittisagul, "Approximating Sensors' Responses of Odor Mixture on Machine Olfaction", en 2009 International Conference on Artificial Intelligence and Computational Intelligence, IEEE, 2009, pp. 60-64. doi: 10.1109/AICI.2009.75.
[53] J. P. Rodríguez, E. J. Girón, D. C. Corrales y J. C. Corrales, "A Guideline for Building Large Coffee Rust Samples Applying Machine Learning Methods", 2018, pp. 97-110. doi: 10.1007/978-3-319-70187-5.8.
[54] J. P. Rodríguez, D. C. Corrales y J. C. Corrales, "A Process for Increasing the Samples of Coffee Rust Through Machine Learning Methods", International Journal of Agricultural and Environmental Information Systems, vol. 9, n°. 2, pp. 32-52, abril 2018. doi: 10.4018/ IJAEIS.2018040103.
[55] L. M. T. de Carvalho, J. G. P. W. Clevers, A. K. Skidmore y S. M. de Jong, "Selection of imagery data and classifiers for mapping Brazilian semideciduous Atlantic forests", International Journal of Applied Earth Observation and Geoinformation, vol. 5, n°. 3, pp. 173186, sep. 2004. doi: 10.1016/j.jag.2004.02.002.
[56] M. F. de Oliveira, A. F. dos Santos, E. H. Kazama, G. de S. Rolim y R. P. da Silva, "Determination of application volume for coffee plantations using artificial neural networks and remote sensing", ComputElectron Agric, vol. 184, p. 106096, mayo 2021. doi: 10.1016/j.compag.2021.106096.